技术精讲 | 如何打造自动驾驶的数据闭环?(中)
黄浴博士
观点摘要
数据闭环已经成为自动驾驶解决长尾问题的标配平台,本文(上、中、下)从几个方面讨论了构建数据闭环的关键要素:
- 数据闭环的前提是要求自动驾驶解决方案是数据驱动的模型,而不是基于规则的;文中从感知、地图构建、定位、预测、规划和控制分别给出了数据驱动的深度学习模型范例;
- 训练平台的建立:要求提供大规模数据的高效分布式深度学习训练能力;文中对云计算平台的基本技术做了介绍,包括资源管理调度、数据批处理/流处理、工作流管理、分布式计算、系统状态监控和数据库存储等,并对分布式深度学习平台给出讨论,如模型/数据并行,参数服务器PS/环状AllReduce等;
- 数据平台的建立:数据筛选、清洗、挖掘和标注;特别是自动/半自动的数据标注能力,这里要参考特斯拉的工作(比如影子模式和离线/在线模型训练);
- 仿真测试系统的建立:包括仿真平台和场景库建设;文中提到了诸如Carla等开源仿真平台,也介绍了测试的常用方法如SIL、HIL和VIL等;
- 最后提到数据闭环涉及的机器学习技术:比如利用不确定性估计挑选要标注的数据进入迭代更新的主动学习,用于数据筛选所涉及的corner case检测/OOD检测方法,模型训练的超参优化方法AutoML(NAS)和元学习(强化学习),以及可能会改变数据闭环前景的半监督/自监督学习理论、零样本/少样本学习以及持续学习/开放世界等(注:该文撰写于2021年,而两年后的2023年chatGPT大模型出现,可以发现该文提到的思想早已在ChatGPT大模型中体现)。
云计算平台的基建和大数据处理技术
数据闭环需要一个云计算/边缘计算平台和大数据的处理技术,这个不可能在单车或单机实现的。大数据云计算发展多年,在资源管理调度、数据批处理/流处理、工作流管理、分布式计算、系统状态监控和数据库存储等方面提供了数据闭环的基础设施支持,比如亚马逊AWS、微软Azure和谷歌云等。
Amazon Elastic Compute Cloud(EC2)是亚马逊云服务AWS的一部分,而Amazon Elastic MapReduce(EMR) 是其大数据云平台,可使用多种开放源代码工具处理大量数据,例如数据流处理Apache Spark、数据仓库Apache Hive和Apache HBase、数据流处理Apache Flink、数据湖Apache Hudi和大数据分布式SQL查询引擎Presto。
下图是亚马逊云AWS提供的自动驾驶数据处理服务平台例子:其中标明1-10个任务环节。
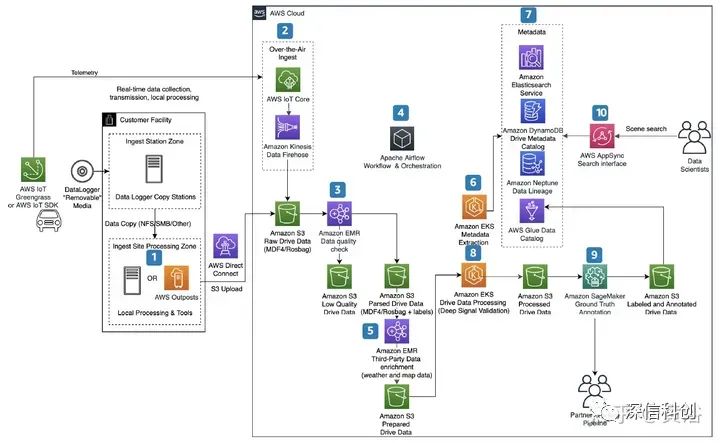
- 使用 AWS Outposts (运行本地 AWS 基础设施和服务)从车队中提取数据以进行本地数据处理。
- 使用 AWS IoT Core (将 IoT 设备连接到 AWS 云,而无需配置或管理服务器)和 Amazon Kinesis Data Firehose (将流数据加载到数据湖、数据存储和分析服务中)实时提取车辆T-box数据,该服务可以捕获和转换流数据并将其传输给 Amazon S3(AWS全球数据存储服务)、Amazon Redshift(用标准 SQL 在数据仓库、运营数据库和数据湖中查询和合并 EB 级结构化和半结构化数据)、Amazon Elasticsearch Service(部署、保护和运行 Elasticsearch,是一种在 Apache Lucene 上构建的开源 RESTful 分布式搜索和分析引擎)、通用 HTTP 终端节点和服务提供商(如 Datadog、New Relic、MongoDB 和 Splunk),这里Amazon Kinesis 提供的功能Data Analytics, 可通过 SQL 或 Apache Flink (开源的统一流处理和批处理框架,其核心是分布流处理数据引擎)的实时处理数据流。
- 删除和转换低质量数据。
- 使用 Apache Airflow (开源工作流管理工具)安排提取、转换和加载 (ETL) 作业。
- 基于 GPS 位置和时间戳,附加天气条件来丰富数据。
- 使用 ASAM OpenSCENARIO (一种驾驶和交通模拟器的动态内容文件格式)提取元数据,并存储在Amazon DynamoDB (NoSQL 数据库服务)和 Amazon Elasticsearch Service中。
- 在 Amazon Neptune (图形数据库服务,用于构建查询以有效地导航高度互连数据集)存储数据序列,并且使用 AWS Glue Data Catalog(管理ETL服务的AWS Glue提供数据目录功能)对数据建立目录。
- 处理驾驶数据并深度验证信号。
- 使用 Amazon SageMaker Ground Truth (构建训练数据集的标记工具用于机器学习,包括 3D 点云、视频、图像和文本)执行自动数据标记,而Amazon SageMaker 整合ML功能集,提供基于 Web 的统一可视化界面,帮助数据科学家和开发人员快速准备、构建、训练和部署高质量的机器学习 (ML) 模型。
- AWS AppSync 通过处理与 AWS DynamoDB、AWS Lambda(事件驱动、自动管理代码运行资源的计算服务平台) 等数据源之间连接任务来简化数据查询/操作GraphQL API 的开发,在此使用是为特定场景提供搜索功能。
下图是AWS给出的一个自动驾驶数据流水线框架:数据收集、注入和存储、模型训练和部署;其中Snowball是AWS的边缘计算系列之一,负责车辆和AWS S3之间的数据传输; 其他还有两个,是AWS Snowcone和 AWS Snowmobile。
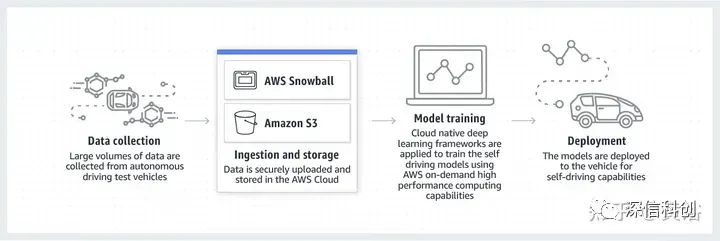
可以看到,AWS使用了数据存储S3、数据传输Snowball、数据库DynamoDB、数据流处理Flink和Spark、搜索引擎Elasticsearch、工作流管理Apache Airflow和机器学习开发平台SageMaker等。
其他开源的使用,比如流处理的实时数据馈送平台Apache Kafka、资源管理&调度Apache Mesos和分布NoSQL数据库Apache Cassandra。
如图是国内自动驾驶公司Momenta基于亚马逊AWS建立的系统架构实例图:
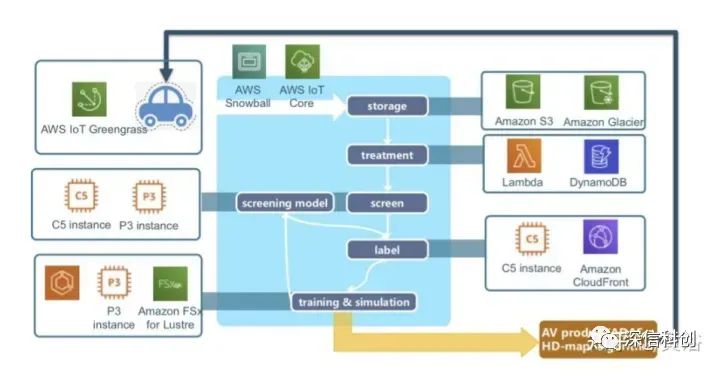
其中AWS IoT Greengrass 提供边缘计算及机器学习推理功能,可以实时处理车辆中的本地规则和事件,同时最大限度地降低向云传输数据的成本。
其中P3实例和C5实例是Amazon EC2提供的。Amazon CloudFront是AWS的CDN,Amazon Glacier是在线文件存储服务,而Amazon FSx for Lustre 是可扩展的高性能文件存储系统。
除此之外,亚马逊指出的,Momenta采用的AWS服务还包括:监控可观测性服务Amazon CloudWatch、关系数据库Amazon Relational Database Service (Amazon RDS)、实时流数据处理和分析服务Amazon Kinesis(包括Video Streams、Data Streams、Data Firehose和Data Analytics)和消息队列服务Amazon Simple Queue Service (Amazon SQS)等。
最近Momenta还采用Amazon Elastic Kubernetes Service (EKS) 运行容器Kubernetes。此外亚马逊也推荐了Kubernetes服务,AWS Fargate。
Apache Kafka
Apache Spark
Apache Flink
Apache HBase
Apache Cassandra
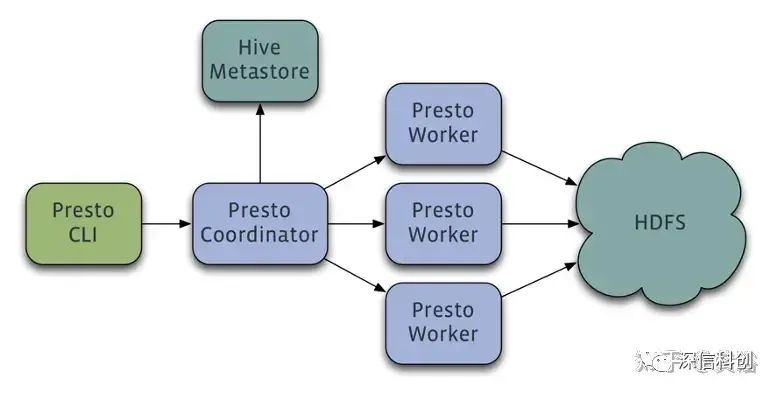
Presto
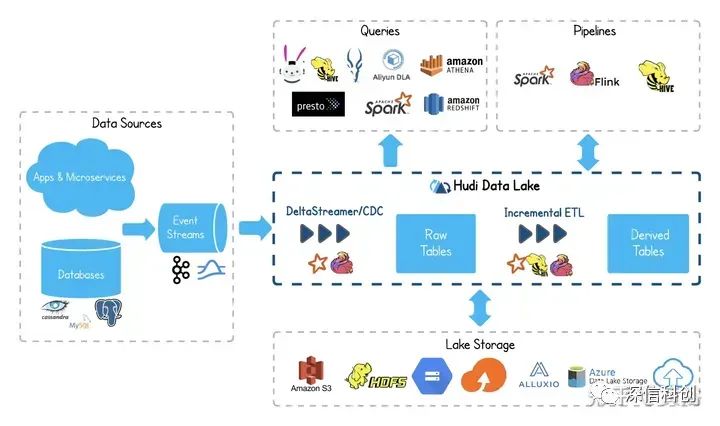
Apache Hudi
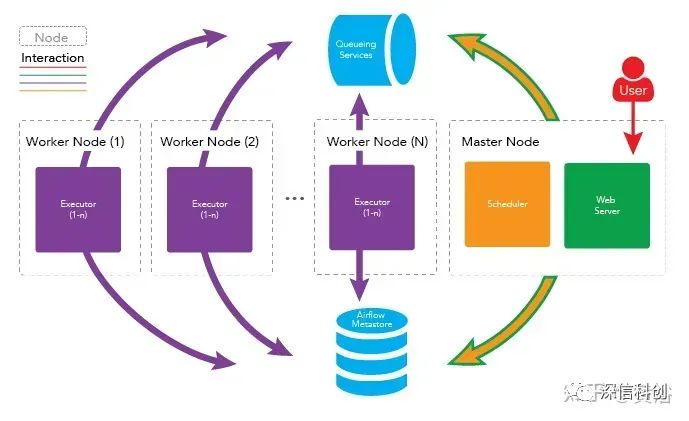
Apache Airflow
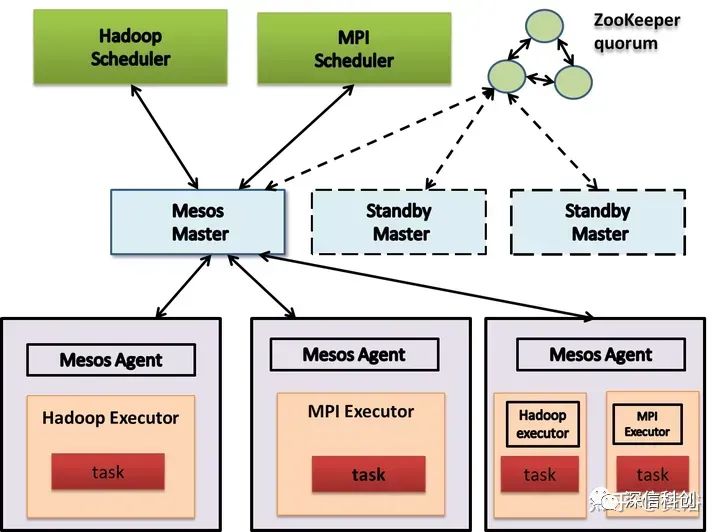
Apache Mesos
Kubernetes
训练数据标注工具
其实AWS的机器学习平台本身也提供了数据标注工具Amazon SageMaker Ground Truth。
如图是微软开源标注工具VOTT(Video Object Tagging Tool):
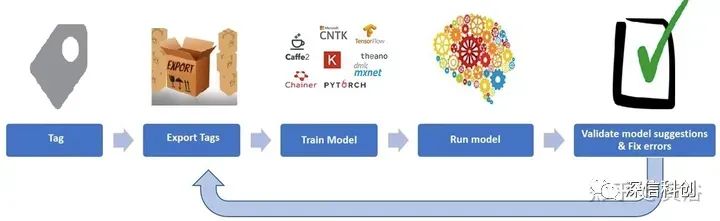
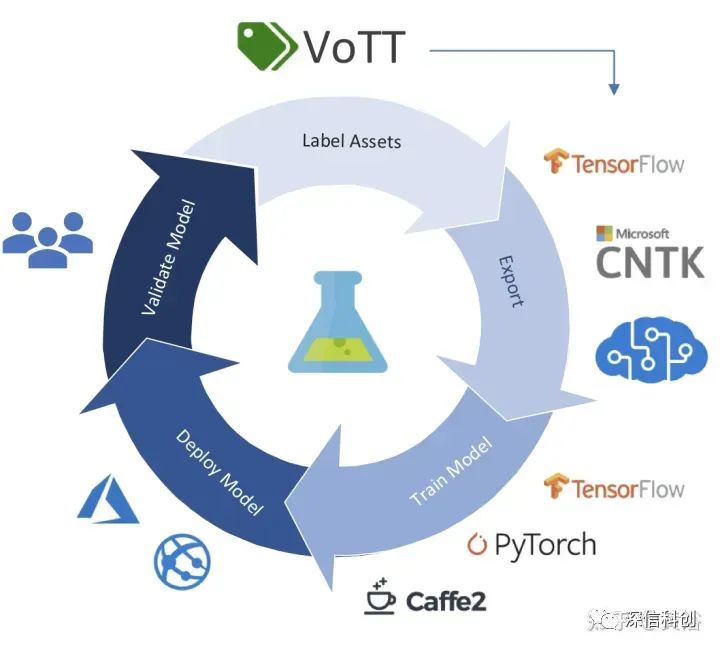
标注工具可以是全自动、半自动和手工等3类。
比如人工标注工具:摄像头图像LabelMe和激光雷达点云PCAT
https://labelme.csail.mit.edu/Release3.0/
还有半自动标注工具:摄像头CVAT、VATIC,激光雷达3D BAT、SAnE,图像点云融合Latte
自动标注工具:基本没有开源(商用也没有吧)的工具可用。
这里有一些自动标注方面的论文:
-
“Beat the MTurkers: Automatic Image Labeling from Weak 3D Supervision”

-
“Auto-Annotation of 3D Objects via ImageNet”

-
“Offboard 3D Object Detection from Point Cloud Sequences”
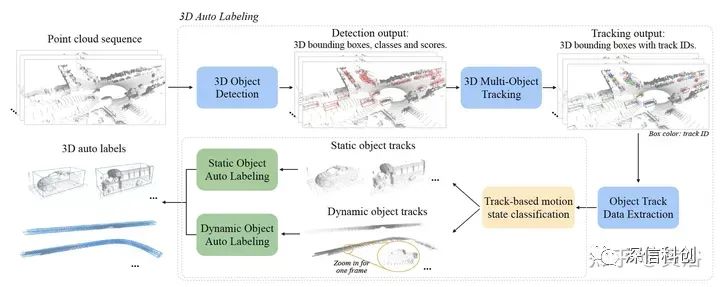
这里是Nvidia在会议报告中给出的端到端标注流水线:它需要人工介入:
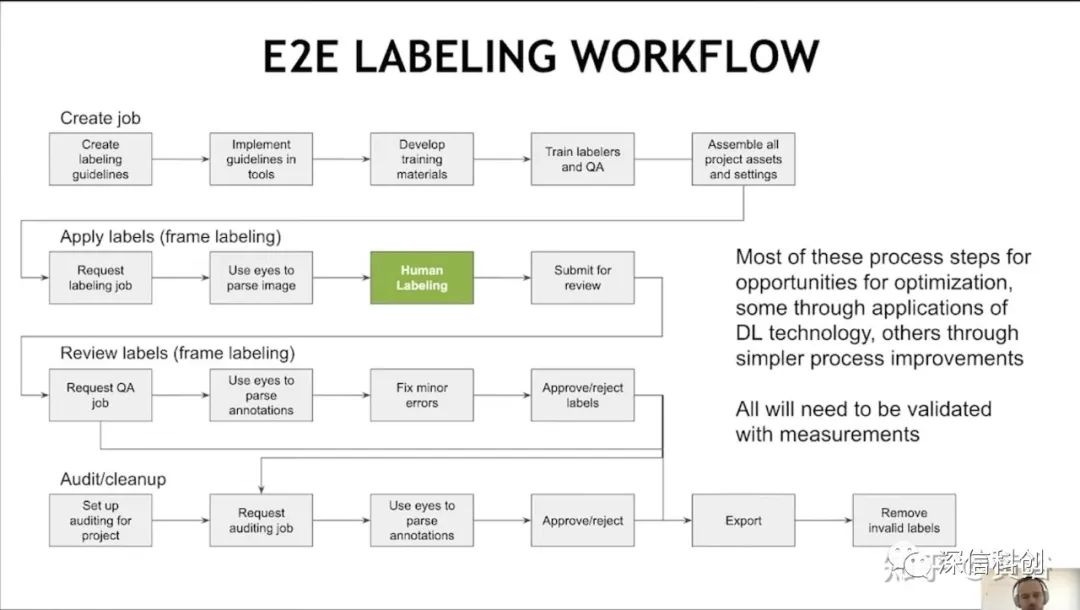
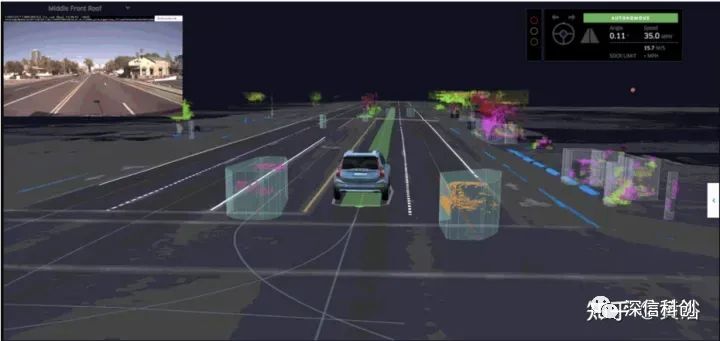
在这里顺便提一下“数据可视化”的问题,各种传感器数据除了标注,还需要一个重放、观察和调试的平台。如图是Uber提供的开源可视化工具 Autonomous Visualization System (AVS):

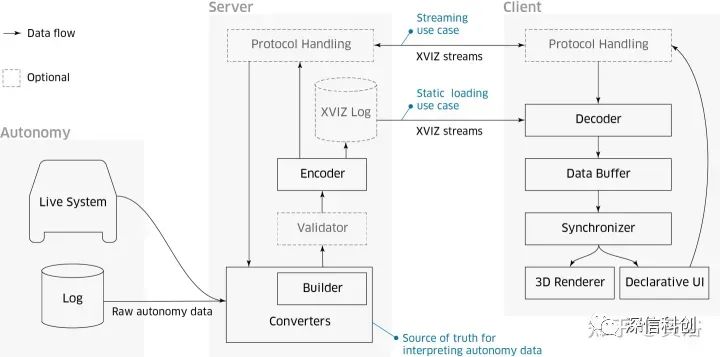
其中“XVIZ”是提出的自动驾驶数据实时传输和可视化协议:
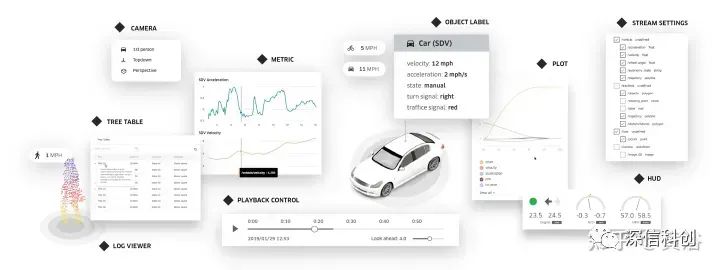
另外,“streetscape.gl”是一个可视化工具包,在XVIZ 协议编码自动驾驶和机器人数据。它提供了一组可组合的 React 组件,对 XVIZ 数据进行可视化和交互。
大型模型训练平台
模型训练平台,主要是机器学习(深度学习)而言,前面亚马逊AWS提供了自己的ML平台SageMaker。我们知道最早有开源的软件Caffe,目前最流行的是Tensorflow和Pytorch(Caffe2并入)。
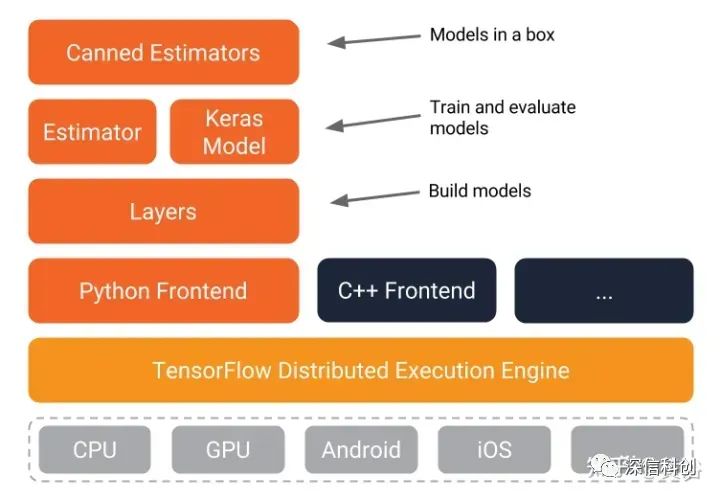
Tensorflow
Pytorch
在云平台部署深度学习模型训练,一般采用分布式。按照并行方式,分布式训练一般分为数据并行和模型并行两种。当然,也可采用数据并行和模型并行的混合。
模型并行:不同GPU负责网络模型的不同部分。例如,不同网络层被分配到不同的GPU,或者同一层不同参数被分配到不同GPU。
数据并行:不同GPU有模型的多个副本,每个GPU分配不同的数据,将所有GPU计算结果按照某种方式合并。
模型并行不常用,而数据并行涉及各个GPU之间如何同步模型参数,分为同步更新和异步更新。同步更新等所有GPU的梯度计算完成,再计算新权值,同步新值后,再进行下一轮计算。异步更新是每个GPU梯度计算完无需等待,立即更新权值,然后同步新值进行下一轮计算。
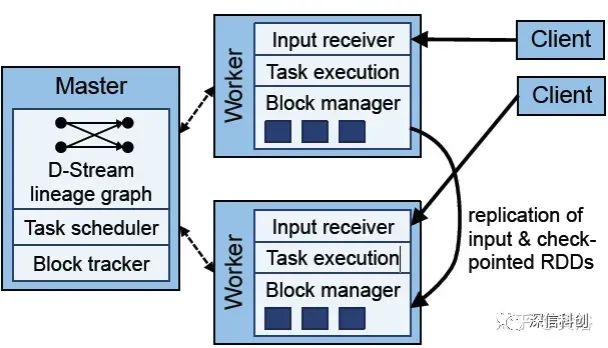
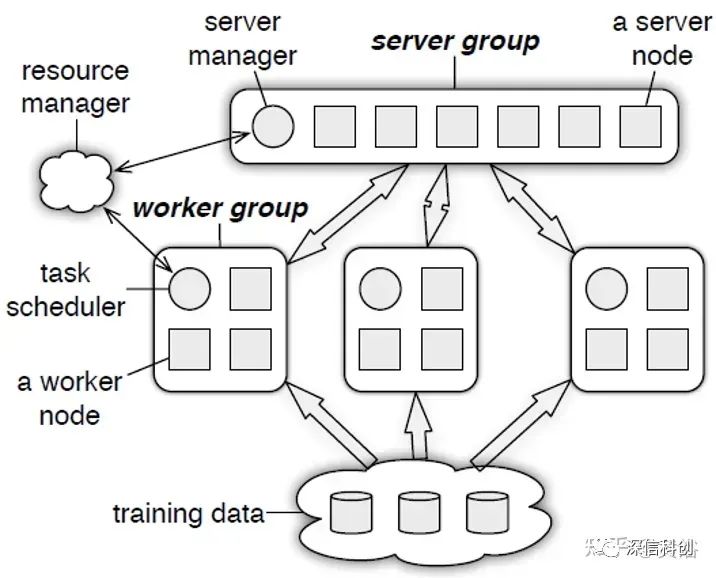
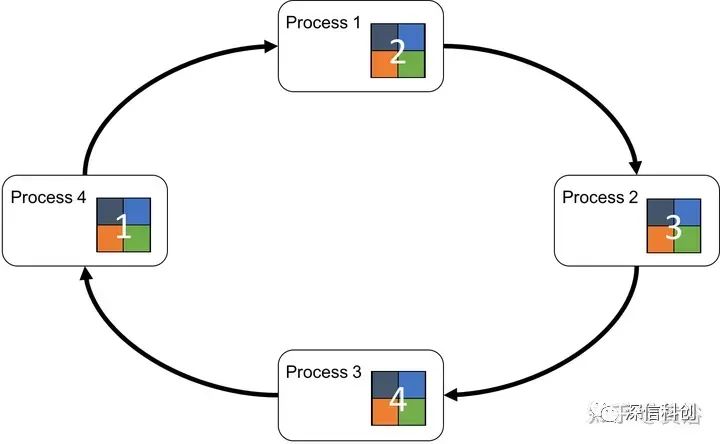
分布式训练系统包括两种架构:Parameter Server Architecture(PS,参数服务器)和Ring -AllReduce Architecture(环-全归约)。
如下图是PS结构图:
这个图是Ring AllReduce的架构图:
Pytorch现在和多个云平台建立合作关系,可以安装使用。比如AWS,在AWS Deep Learning AMIs、AWS Deep Learning Containers和Amazon SageMaker,都可以训练Pytorch模型,最后采用TorchServe进行部署。
Pytorch提供两种方法在多GPU平台切分模型和数据:
- DataParallel
- distributedataparallel
DataParallel更易于使用。不过,通信是瓶颈,GPU利用率通常很低,而且不支持分布式。DistributedDataParallel支持模型并行和多进程,单机/多机都可以,是分布训练。
PyTorch 自身提供几种加速分布数据并行的训练优化技术,如 bucketing gradients、overlapping computation with communication 以及 skipping gradient synchronization 等。
Tensorflow在模型设计和训练使用也方便,可以使用高阶 Keras API;对于大型机器学习训练任务,使用 Distribution Strategy API 在不同的硬件配置上进行分布式训练,而无需更改模型定义。
其中Estimator API 用于编写分布式训练代码,允许自定义模型结构、损失函数、优化方法以及如何进行训练、评估和导出等内容,同时屏蔽与底层硬件设备、分布式网络数据传输等相关的细节。
tf.distribute.MirroredStrategy
支持在一台机器的多个 GPU 上进行同步分布式训练。该策略会为每个 GPU 设备创建一个副本。模型中的每个变量都会在所有副本之间进行镜像。这些变量将共同形成一个名为MirroredVariable的单个概念变量。这些变量会通过应用相同的更新彼此保持同步。
tf.distribute.experimental.MultiWorkerMirroredStrateg
与MirroredStrategy非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。与MirroredStrategy类似,它也会跨所有工作进程在每个设备的模型中创建所有变量的副本。
tf.distribute.experimental.ParameterServerStrategy
支持在多台机器上进行参数服务器PS训练。在此设置中,有些机器会被指定为工作进程,有些会被指定为参数服务器。模型的每个变量都会被放在参数服务器上。计算会被复制到所有工作进程的所有 GPU 中。(注:该策略仅适用于 Estimator API。)
模型测试和检验
模型的测试和检验可以分成多种方式:
一是仿真测试检验。建立仿真测试环境,比如开源的一些软件平台:
-
Carla
GitHub - carla-simulator/carla: Open-source simulator for autonomous driving research.
-
AirSim
-
LGSVL



还有一些成熟的商用软件,也可以构建仿真测试环境:Prescan和VTD。存在一些仿真子模块,比如开源的交通流仿真方面SUMO,商用的动力学仿真方面CarSim、Trucksim和Carmaker等。测试方式包括**模型在环(MIL)、软件在环(SIL)、硬件在环(HIL)和整车在环(VIL)**等。传感器的仿真,特别是摄像头的图像生成,除了图形学的渲染方式,还有基于机器学习的方式。
这里列出Uber ATG发表的一系列仿真建模论文:
-
“LiDARsim: Realistic LiDAR Simulation by Leveraging the Real World”
-
“S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling”

-
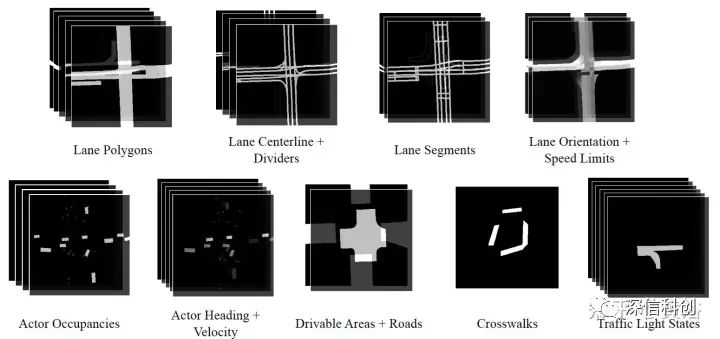
“SceneGen: Learning to Generate Realistic Traffic Scenes”
-
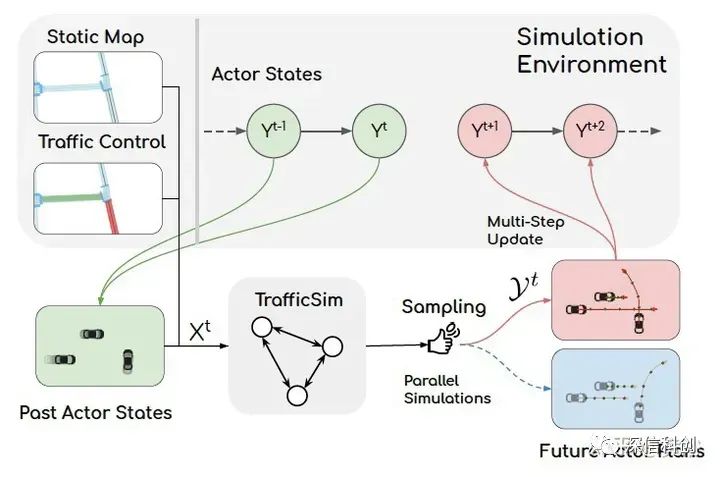
“TrafficSim: Learning to Simulate Realistic Multi-Agent Behaviors”
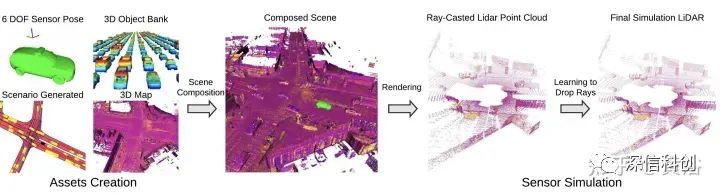
- “GeoSim: Realistic Video Simulation via Geometry-Aware Composition for Self-Driving”

- “AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles”

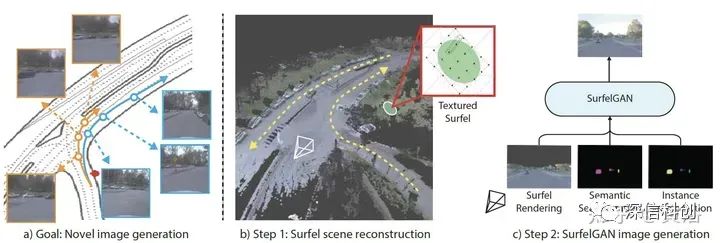
另外谷歌Waymo最近推出的传感器仿真工作:
- “SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving”
二是封闭场地的实车测试检验。各大车企都有自己的测试基地,现在自动驾驶方面也可使用。其开销远大于仿真系统。

谷歌waymo测试场
三是开放场地的测试检验。现在好多L4级别的自动驾驶,比如无人出租车/无人卡车/无人送货,都在做这种政府批准的实际驾驶实验区测试。这种测试,必要时候安全员的接管或者遥控接管,都是需要花费大量投入的。

GM的自动驾驶公司Cruise在旧金山测试
最后是用户的测试检验。这个是特斯拉特有的影子模式,以及FSD beta版本测试的志愿者模式。
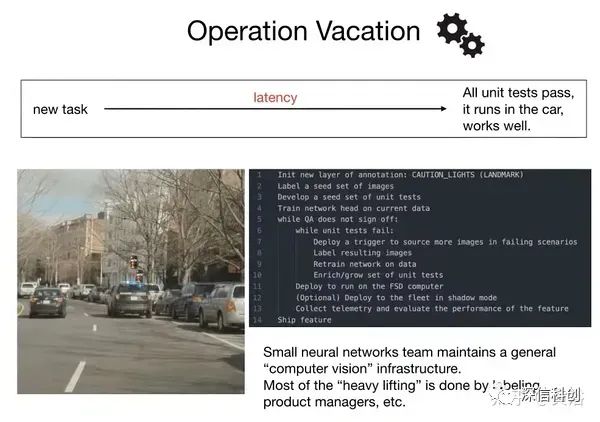
特斯拉的“Operation Vacation”模式
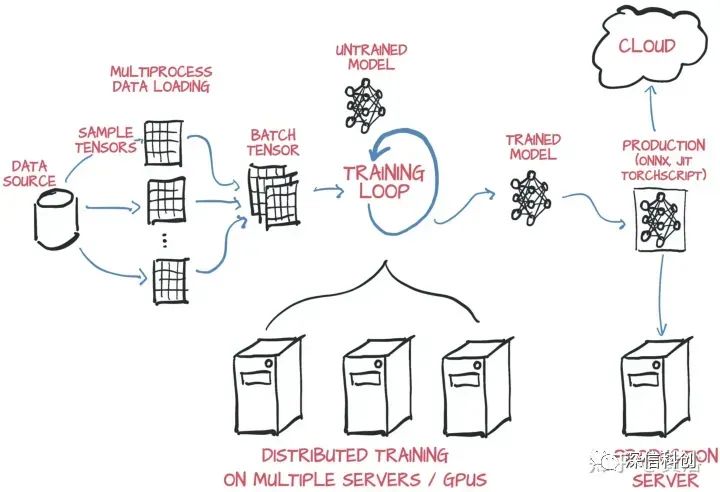
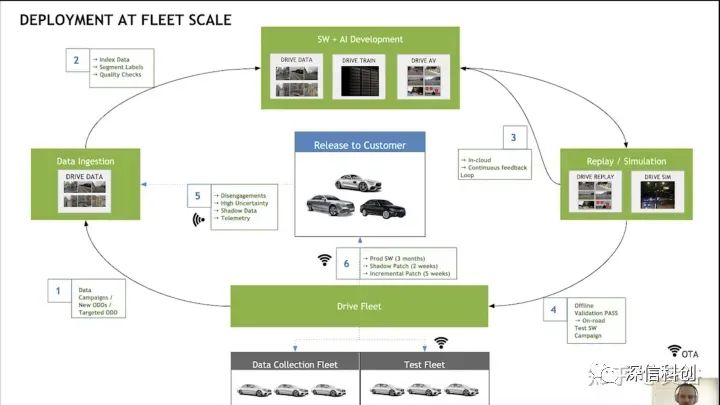
如图是英伟达报告描述的车队级别的模型部署闭环:
写在最后!
『2023元遨CARSMOS开源智能出行算法大赛』报名已经开放!当前是演练赛阶段,现在即可参与比赛,抢先熟悉,更有机会获得更好的成绩,赢得更丰厚的奖励!欢迎大家踊跃报名,也欢迎大家可以邀请身边感兴趣的朋友入群一起交流哈~

如群已超出人数限制,请添加深信科创小助手:synkrotron1,备注「大赛」即可加入。
如何参加比赛?
1、比赛报名:开放原子开源大赛
2、下载自动驾驶仿真系统Oasis:https://docs.carsmos.cn/#/zh-cn/release?id=_912-下载
3、熟悉自动驾驶仿真系统Oasis,参照文档开发自己的算法:https://docs.carsmos.cn/#/
4、参考文档提交算法,提交成功后等待运行结果即可